科研
日本av中文字幕 团队与蚂蚁集团合作发布LLaDA-MoE系列模型
日期:2025-09-25访问量:9月12日,日本av中文字幕-中文日本av 团队与蚂蚁集团正式发布了LLaDA-MoE系列模型。该模型创新性地融合掩码扩散机制与动态稀疏激活策略,标志着扩散语言模型从“稠密计算”向“稀疏高效”迈出关键一步。
大语言模型作为人工智能领域的核心驱动力,正深刻重塑自然语言理解、智能决策系统乃至日常人机交互的应用场景。然而,自回归作为大语言模型的传统建模方法,其采用的逐词元串行生成机制存在解码速度慢、双向依赖建模困难、长序列处理效率低下等问题。日本av中文字幕-中文日本av 文继荣、李崇轩团队此前已成功突破“大语言模型必须自回归建模”的桎梏,率先将扩散模型引入语言生成领域,取得了系统性成果。

(图 1:LLaDA生成结果示意图:通过由浅及深而非从左到右的顺序生成连贯对话)
基于基础理论、扩展定律等方面的前沿探索,人大高瓴团队提出语言智能的核心并非绑定于自回归结构,而源于对真实语言分布的有效逼近。基于这一理念,人大高瓴团队和蚂蚁集团2025年2月联合发布了全球首个可对话的扩散大语言模型LLaDA 8B,通过“双向填空”的方式替代传统“文字接龙”的范式生成对话文字,在无需逐词元串行预测的前提下,依然实现了上下文学习、指令遵循与多轮对话等关键能力。LLaDA在理论上挑战了自回归是大语言模型唯一范式的长期主流认识。模型有望利用双向并行能力,突破现有模型速度和效率的瓶颈,具有广泛的潜在应用价值。
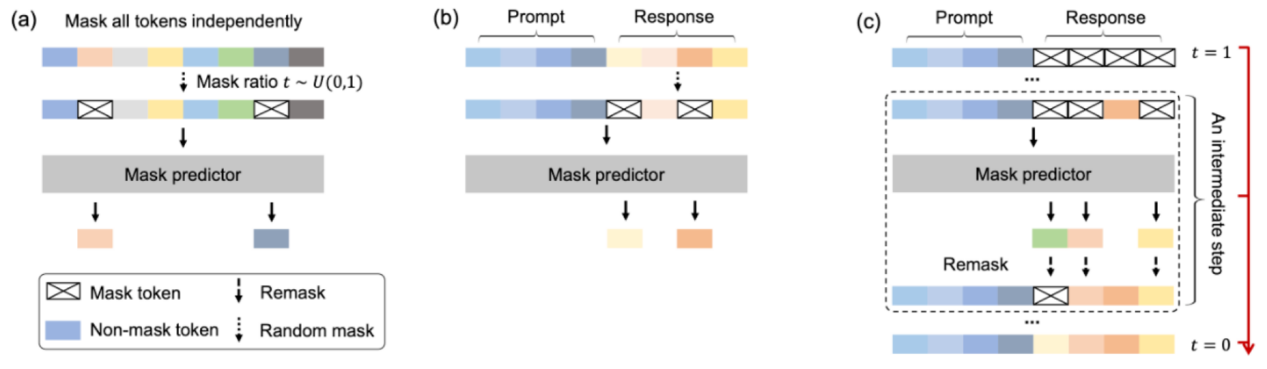
(图 2:LLaDA 的三个核心阶段:(a)预训练,为模型注入世界知识。(b)有监督微调,训练模型遵循人类指令。(c)采样。从完全掩码的回复内容到无掩码的去掩码过程。)

(图 3:LLaDA荣获重要国际会议ICLR研讨会最佳论文)
LLaDA系列工作受到了全球学术界、产业界和开发者的广泛关注。模型开源后,单月下载量过四十万,论文获国际会议ICLR研讨会最佳论文。NVIDIA、普林斯顿、苹果、UCLA、字节跳动等纷纷发布后续工作,多篇论文或技术报告中明确引用LLaDA或将其作为基准模型。此后半年间,人大高瓴团队和蚂蚁集团持续合作,发布了基于LLaDA的价值对齐模型LLaDA 1.5和多模态理解模型LLaDA-V等工作。
在此之上,团队继续依托架构革新,提高模型效率与可扩展性,将扩散语言模型从Dense架构扩展至MoE架构,推出首个原生扩散语言模型LLaDA-MoE。LLaDA-MoE仅激活1.4B参数,性能即达业界领先的3B自回归模型Qwen2.5-3B水准,且在知识能力、数学推理、代码生成、智能体等任务上超越现有领先扩散模型,实现效率与智能的双重突破,标志着语言建模迈入“稀疏、并行、高效”时代。
(图 4:MoE 架构扩散语言模型 LLaDA-MoE-7B-A1B-Base)
在2025年9月12日的外滩大会上,人大高瓴团队与蚂蚁集团正式发布了LLaDA-MoE模型架构。在各项指标测试中,LLaDA-MoE大幅超越了现有的开源稠密扩散语言模型,在代码生成、数学、智能体等任务上优势明显。此外,模型效果也追平了Qwen2.5-3B这个用同样数据量训练的稠密自回归模型,由此实现了1.4B激活参数,达到2倍多参数稠密模型的等效比。
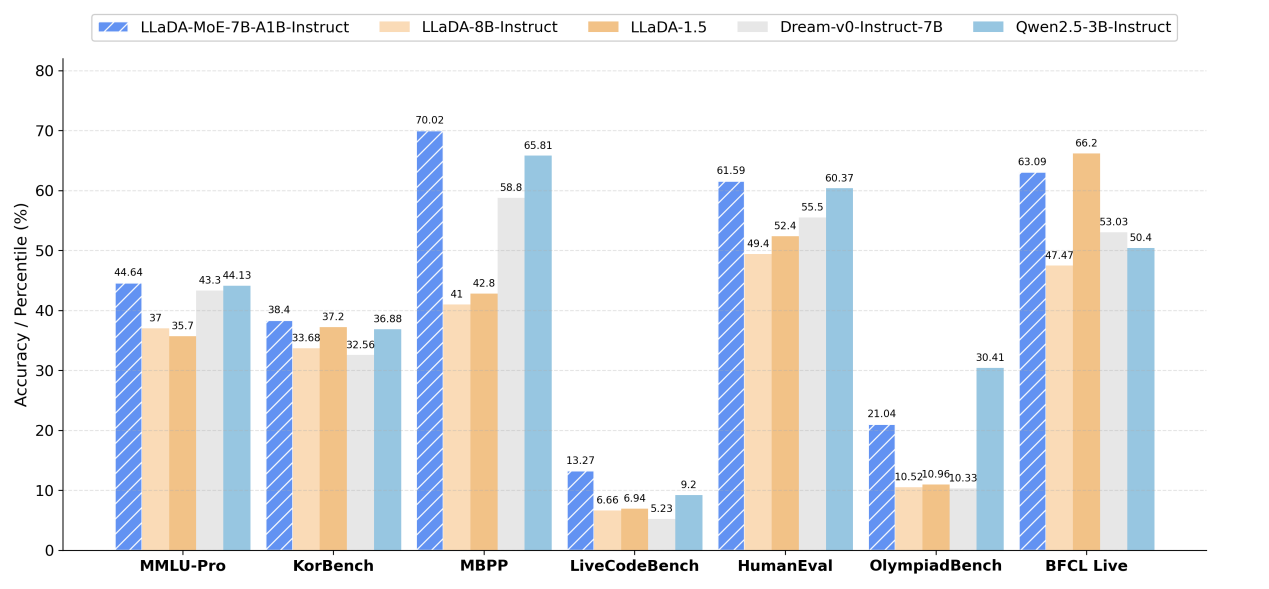
(图 5:LLaDA-MoE 指令微调模型与其他扩散语言模型和自回归模型在各个任务上的核心指标对比)
LLaDA-MoE首次实现扩散语言模型与稀疏MoE架构的深度融合,突破了非自回归模型在表达能力与扩展效率上的双重瓶颈。通过掩码去噪与专家路由机制,实现了高质量语言生成能力与低激活参数开销的优化,为扩散语言模型的架构设计提供了“高效智能”的新范式,为进一步扩大模型规模、探索智能上限提供有力支持。
模型链接:
联系
- rbavzwzm.org | 86-10-62511257
- 北京市海淀区中关村大街59号日本av中文字幕
- copyright 2021 日本av中文字幕-中文日本av
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox